Android and Kotlin flows: shifting your mindset

Kotlin and me
When I switched from years of programming in Java — and traditional imperative programming in general — to Kotlin in Android, two concepts were really foreign and forced me to change the way I think about programs: coroutines and flows.
Although I had some experience with RxJava and concurrent programming from Java, took me a while to get used to the way equivalent functionality is written in Kotlin; in particular the coroutine “write sequentially but (maybe) execute concurrently” paradigm — not coincidentally named structured concurrency — and the flow’s “applications are streams of data consumed concurrently” paradigm caused me quite a bit of trouble on the way I visualize and write programs.
If you’re struggling the same way I did, I hope this article works as another tool to make the concept of flows a bit more clear, by going through it in a more in-depth detail.
At the end of this article you will find a link to the source code used in this discussion.
The general idea
When using flows, the developer does 4 things:
- Implements code that generates the data — a stream of random numbers, content from a file from the local disk, a streaming video from the Internet, button presses in the UI — and sends it to one or more consumers, called flow collectors
- Instantiates a flow object and passes the code above to it
- Implements the flow collector, responsible for processing the data
- Decides when in the program the flow will start producing and consuming data, providing the flow collector implemented above at that moment.
Flow execution is synchronous, in the sense that it follows these steps once execution starts: generate data => send to flow collector => flow collector processes
For that reason, the interfaces associated with flows are suspending functions, allowing flows to be launched and executed asynchronously in separate threads, concurrently with the main thread.
Here is a minimalistic implementation
I think it makes a bit easier to understand all these ideas if we look at a very simplified definition and implementation of the flow and flow collector interfaces: Flow and FlowCollector.
The Flow and FlowCollector interfaces
public fun interface FlowCollector<in T> {
public suspend fun emit(value: T): kotlin.Unit
}
public interface Flow<out T> {
public suspend fun collect(collector: kotlinx.coroutines.flow.FlowCollector<T>): kotlin.Unit
}As it can be seen here, the Flow interface exposes the collect() function with a flow collector object as an argument. collect() is invoked when the program is ready to start generating and consuming data; it’s the signal for the flow to start doing that (we’ll show how this is actually done in a bit).
The FlowCollector functional interface exposes the generic emit() function; this is the common interface implemented by flow collectors for the flow to send —a.k.a. emit —data into the flow collector (more details below).
On top of these 2 interfaces, the framework provides a flow builder function, simply named flow(), responsible for constructing an object implementing the Flow interface.
The flow framework implementation
Now let’s dive into the minimalistic implementation of the 2 interfaces we introduced in the previous section, as well as the flow() function.
We’ll start with the verbose implementation — explicit implementation and object creation, almost no lambdas — then use Kotlin language features to arrive at the final, more concise form for it.
1. fun <T> flow(emitter: suspend (FlowCollector<T>) -> Unit): Flow<T> =
object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
emitter(collector)
}
}
2. val fc = object : FlowCollector<String> {
override suspend fun emit(value: String) {
print(value)
}
}
3. val emitter : suspend (FlowCollector<String>) -> Unit = { flowCollector ->
flowCollector.emit("A")
flowCollector.emit("B")
flowCollector.emit("C")
}
4. val myFlow = flow(emitter)
5. fun test() {
GlobalScope.launch { // <= collect() is suspending, need a coroutine
myFlow.collect(fc)
}
}Let’s look at it item by item
Item 1: the flow() function implementation
The flow() function implemented here accepts a function type with a flow collector argument then returns an instance of the Flow interface, implementing the collect() function.
In this simplest implementation the collect() function simply invokes the function — here assigned to the emitter argument — passing the flow collector to it; the expectation is that the emitter will start generating and emitting data to the flow collector when the collect() function is invoked, the flow has no knowledge about the emitter’s implementation.
Item 2: the FlowCollector implementation
An instance of a concrete implementation of a flow collector is created here, implementing the emit() interface.
The emit() method is expected to be invoked from the emitter, passing data to the flow collector to be processed. Here we are simply printing the string passed to it.
Item 3. Creating the emitter
Here the variable emitter is initialized with the function to be passed to the flow builder. The implementation is very simple, it will just emit 3 strings in a row; could be something as complicated as pulling encrypted, multiplexed data, decrypting it and demuxing it before sending to the flow collector.
Item 4: the flow creation
Here we are creating the Flow object, providing the emitter function to be invoked when the collect() function is called.
Item 5: the code starts generating and collecting data
Finally here we define function test(), which, when invoked, will trigger the whole sequence:
- test() invokes collect(), passing the flow controller (notice the coroutine scope needed since these are suspending functions)
- collect() invokes the emitter function, passing the flow controller
- the emitter function calls emit() on the flow controller 3 times, passing strings
- emit() prints each of the received strings
The use of suspending functions allows for invoking flows concurrently with any other threads being executed by the application.
It’s also important to notice that this implementation is a cold flow: whenever collect() is called with a a new flow collector the flow runs again, sending the same data to the new collector; collect() can be can be called passing different flow collectors, each one processing the data in a different way.
Making it more concise
Next we’ll make a few changes to the implementation we studied in the previous section to make it more concise, thanks to features supported by the Kotlin language.
Remove the explicit creation of the flow collector
Because FlowCollector is defined as a functional or SAM (Single Abstract Method) interface, we don’t need to create a FlowCollector object implementing emit() as we did in line 2; we can simply pass a lambda to the collect() function and SAM conversion will take care of it.
Similarly, the emitter function can be passed directly to flow() as a lambda.
This way the code becomes:
1. fun <T> flow(emitter: suspend (FlowCollector<T>) -> Unit): Flow<T> =
object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
emitter(collector)
}
}
2. val myFlow = flow { flowCollector ->
flowCollector.emit("A")
flowCollector.emit("B")
flowCollector.emit("C")
} // <= pass the emitter as a lambda
3. fun test() {
GlobalScope.launch {
myFlow.collect { value ->
print(value)
} // <= pass the flow collector as a lambda
}
}Eliminate the direct reference to the flowCollector argument in the emitter lambda
If we pass a receiver to the flow() function instead of an object, we can call the emitter function on the flow collector object without having to explicitly invoke the instance, since the object reference is implicitly passed to the lambda.
Here is the new code:
1. fun <T> flow(emitter: suspend FlowCollector<T>.() -> Unit): Flow<T> =
object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
collector.emitter()
}
}
2. val myFlow = flow { // flow collector reference is implicit here
emit("A") // <= is the same as this.emit()
emit("B")
emit("C")
}
3. fun test() {
GlobalScope.launch {
myFlow.collect { value ->
print(value)
}
}
}So there you have it. The first line is very similar to the implementation provided by the framework; the other 2 lines are the actual code for using flows.
And that’s just the starting line
This article covered the most basic aspects of flows, and I hope it gives the reader a starting point from where to explore the quite vast set of functionality available in this framework.
Some examples of extension functions and specialized flow classes are:
- filter/filterNot
- map/mapNotNull
- onEach
- launchIn
- Iterable.asFlow
- Sequence.asFlow
- SharedFlow
- StateFlow
- etc.
As promised, link to the source
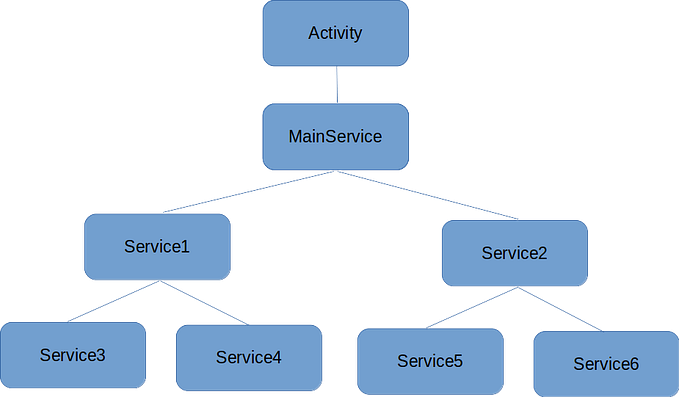
Keep in mind that this is just an illustration and is not how you’d be doing this in practice (e.g. normally one would not put business logic in the Activity).
Also I added a few extra logs to the code to show the sequential nature of the execution as well as the threads used for execution.
References
[1] Moskała, M., Kotlin Coroutines — Deep Dive
[2] Kotlin coroutines documentation